 مارک زاکربرگ با پیشگویی «خلق و کشف چیزهای جدیدی که امروز قابل تصور نیستند»، اعلام میکند که «توسعه ابرهوش در دسترس است». داریو آمودی نیز وعده دو برابر شدن طول عمر انسان یا حتی «رسیدن به سرعت گریز» از مرگ را میدهد و میگوید هوش مصنوعی قدرتمند «ممکن است تا سال ۲۰۲۶ فرا رسد [و] در اکثر زمینههای مربوطه از یک برنده جایزه نوبل باهوشتر باشد.» سم آلتمن هم با اشاره به آرمان مقدس این صنعت یعنی هوش عمومی مصنوعی (AGI) میگوید: «اکنون مطمئنیم که میدانیم چگونه AGI بسازیم.» او معتقد است که بهزودی هوش مصنوعی ابرهوشمند میتواند «کشف و نوآوریهای علمی را فراتر از آنچه ما به تنهایی قادر به انجام آن هستیم، شتاب بخشد.»
مارک زاکربرگ با پیشگویی «خلق و کشف چیزهای جدیدی که امروز قابل تصور نیستند»، اعلام میکند که «توسعه ابرهوش در دسترس است». داریو آمودی نیز وعده دو برابر شدن طول عمر انسان یا حتی «رسیدن به سرعت گریز» از مرگ را میدهد و میگوید هوش مصنوعی قدرتمند «ممکن است تا سال ۲۰۲۶ فرا رسد [و] در اکثر زمینههای مربوطه از یک برنده جایزه نوبل باهوشتر باشد.» سم آلتمن هم با اشاره به آرمان مقدس این صنعت یعنی هوش عمومی مصنوعی (AGI) میگوید: «اکنون مطمئنیم که میدانیم چگونه AGI بسازیم.» او معتقد است که بهزودی هوش مصنوعی ابرهوشمند میتواند «کشف و نوآوریهای علمی را فراتر از آنچه ما به تنهایی قادر به انجام آن هستیم، شتاب بخشد.»
آیا باید گفتههای آنها را باور کنیم؟ نه، اگر به علم هوش انسانی اعتماد کنیم و صرفاً به سیستمهای هوش مصنوعی که این شرکتها تاکنون تولید کردهاند، نگاه کنیم.
ویژگی مشترکی که در چتباتهایی مانند ChatGPT از اوپنایآی، Claude از آنتروپیک، Gemini از گوگل، و هر آنچه متا این هفته محصول هوش مصنوعی خود مینامد، وجود دارد، این است که همگی در درجه اول «مدلهای زبان بزرگ» هستند. اساساً، آنها مبتنی بر جمعآوری حجم فوقالعادهای از دادههای زبانی (که بخش عمده آن در اینترنت کدگذاری شده است)، یافتن همبستگی بین کلمات (دقیقتر بگوییم، زیرکلماتی به نام «توکنها») و سپس پیشبینی خروجی مورد انتظار پس از دریافت یک ورودی خاص (Prompt) هستند. با وجود تمام پیچیدگی ادعایی هوش مصنوعی زایشی، آنها در هسته خود واقعاً مدلهایی از زبان محسوب میشوند.
مشکل اینجاست که طبق علوم اعصاب کنونی، تفکر انسان تا حد زیادی مستقل از زبان انسان است؛ و ما دلایل کمی داریم که باور کنیم مدلسازیهای هرچه پیچیدهتر از زبان، نوعی از هوش را ایجاد خواهد کرد که همسطح یا فراتر از تواناییهای ما باشد. انسانها از زبان برای انتقال نتایج ظرفیت خود برای استدلال، شکلدهی به انتزاعات و تعمیمها، یا همان چیزی که میتوانیم هوش بنامیم، استفاده میکنند. ما از زبان برای فکر کردن استفاده میکنیم، اما این امر زبان را همارز با تفکر نمیسازد. درک این تمایز، کلید جداسازی حقایق علمی از گمانهزنیهای علمی-تخیلی مدیران عامل مشتاق هوش مصنوعی است.
فضای پُرشور هوش مصنوعی بیوقفه این ایده را ترویج میکند که ما در آستانه خلق چیزی به باهوشی انسانها یا حتی «ابرهوشی» هستیم که ظرفیتهای شناختی ما را کوچک خواهد ساخت. طبق این دیدگاه، اگر مقادیر زیادی از دادههای جهان را جمعآوری کرده و آن را با قدرت محاسباتی هرچه قویتر (بخوانید: تراشههای انویدیا) ترکیب کنیم تا همبستگیهای آماری خود را بهبود بخشیم، آنگاه معجزهآسا به AGI دست خواهیم یافت. مقیاسدهی، تنها چیزی است که نیاز داریم.
اما این نظریه، از نظر علمی بهشدت معیوب است. مدلهای زبان بزرگ (LLM) صرفاً ابزارهایی هستند که عملکرد ارتباطی زبان را تقلید میکنند، نه فرآیند شناختی مجزا و متمایز تفکر و استدلال را، مهم نیست که چه تعداد مراکز داده بسازیم.
ما از زبان برای فکر کردن استفاده میکنیم، اما این امر زبان را همارز با تفکر نمیسازد.
سال گذشته، سه دانشمند مقالهای را در قالب یک تفسیر در مجله نیچر (Nature) منتشر کردند که با شفافیتی ستودنی عنوان داشت: «زبان در درجه اول ابزاری برای ارتباط است نه تفکر.» این مقاله که به نویسندگی مشترک اِولینا فدورنکو (MIT)، استیون تی. پیانتادوسی (UC Berkeley) و ادوارد اِی.اِف. گیبسون (MIT) منتشر شد، خلاصهای جامع از دههها تحقیق علمی در مورد رابطه بین زبان و تفکر است و دو هدف دارد: اول، فروپاشی این تصور که زبان باعث ایجاد توانایی ما برای تفکر و استدلال میشود، و دوم، تقویت این ایده که زبان به عنوان یک ابزار فرهنگی تکامل یافته است که ما از آن برای به اشتراک گذاشتن افکارمان با یکدیگر استفاده میکنیم.
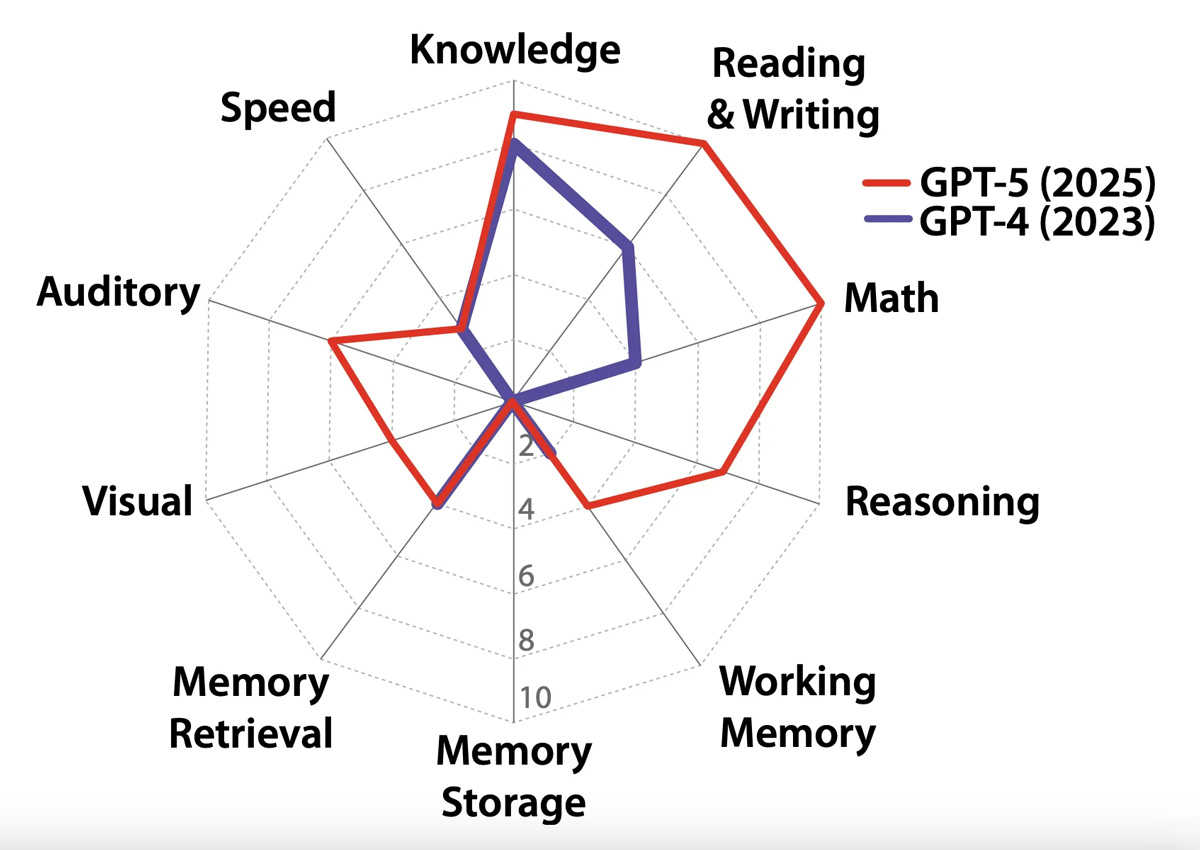
بیایید هر یک از این ادعاها را به نوبه خود بررسی کنیم. وقتی به تفکر خود میاندیشیم، اغلب این حس به وجود میآید که ما به یک زبان خاص فکر میکنیم، و بنابراین، به خاطر زبان خود فکر میکنیم. اما اگر این درست بود که زبان برای تفکر ضروری است، پس حذف زبان نیز باید توانایی ما برای تفکر را از بین ببرد. این اتفاق نمیافتد. تکرار میکنم: حذف زبان، توانایی ما برای تفکر را از بین نمیبرد. و ما این را به چند دلیل تجربی میدانیم.
اول، با استفاده از تصویربرداری پیشرفته رزونانس مغناطیسی عملکردی (fMRI)، میتوانیم فعال شدن بخشهای مختلف مغز انسان را هنگام انجام فعالیتهای ذهنی مختلف مشاهده کنیم. همانطور که مشخص شده است، هنگامی که ما درگیر فعالیتهای شناختی گوناگون میشویم—برای مثال حل یک مسئله ریاضی، یا تلاش برای درک آنچه در ذهن انسان دیگری میگذرد—بخشهای مختلفی از مغز ما به عنوان بخشی از شبکههایی که متمایز از توانایی زبانشناختی ما هستند، روشن میشوند.
دوم، مطالعات روی انسانهایی که تواناییهای زبانی خود را به دلیل آسیب مغزی یا اختلالات دیگر از دست دادهاند، به طور قاطع نشان میدهد که این فقدان، توانایی کلی تفکر را مختل نمیکند. فدورنکو و همکارانش اظهار میکنند که «شواهد صریح و روشن است» که «موارد بسیاری از افرادی وجود دارند که دچار اختلالات شدید زبانشناختی هستند… اما با این وجود، توانایی دست زدن به بسیاری از اشکال تفکر در آنها دست نخورده باقی مانده است.» این افراد میتوانند مسائل ریاضی را حل کنند، دستورالعملهای غیرکلامی را دنبال کنند، انگیزه دیگران را درک کنند و درگیر استدلال شوند—از جمله استدلال منطقی رسمی و استدلال علّی در مورد جهان.
اگر میخواهید این موضوع را به طور مستقل برای خودتان بررسی کنید، یک راه ساده وجود دارد: یک نوزاد پیدا کنید و او را تماشا کنید (زمانی که خواب نیست). بدون شک آنچه مشاهده خواهید کرد، یک انسان کوچک است که با کنجکاوی دنیای اطراف خود را کاوش میکند، با اشیا بازی میکند، صداهایی در میآورد، از چهرهها تقلید میکند و از تعاملات و تجربیات میآموزد، همه اینها پیش از یادگیری صحبت کردن. همانطور که آلیسون گوپنیک، دانشمند شناختی، اشاره میکند: «مطالعات نشان میدهد که کودکان در مورد جهان به همان شیوهای که دانشمندان عمل میکنند، میآموزند—یعنی از طریق انجام آزمایشها، تحلیل آمار و تشکیل نظریههای شهودی در مورد قلمروهای فیزیکی، بیولوژیکی و روانشناختی.» نوزادان ممکن است هنوز نتوانند از زبان استفاده کنند، اما مسلماً آنها در حال تفکر هستند! و هر پدر و مادری از تماشای ظهور شناخت فرزندش در طول زمان لذت میبرد.

بنابراین، از دیدگاه علمی، زبان تنها یک جنبه از تفکر انسان است، و بخش عمدهای از هوش ما شامل ظرفیتهای غیرزبانشناختی ما میشود. پس چرا بسیاری از ما به طور شهودی خلاف این را حس میکنیم؟
این ما را به دومین ادعای اصلی مقاله نیچر توسط فدورنکو و همکارانش میرساند، مبنی بر اینکه زبان در درجه اول ابزاری است که ما از آن برای به اشتراک گذاشتن افکارمان با یکدیگر استفاده میکنیم—یا به عبارت آنها «یک کد ارتباطی کارآمد». این امر با این واقعیت تأیید میشود که در میان تنوع گسترده زبانهای انسانی، آنها دارای ویژگیهای مشترکی هستند که آنها را «آسان برای تولید، آسان برای یادگیری و درک، مختصر و کارآمد برای استفاده، و مقاوم در برابر نویز (اختلال)» میسازد.
حتی بخشهایی از صنعت هوش مصنوعی نیز نسبت به LLMها منتقد میشوند
بدون ورود بیش از حد به جزئیات زبانشناختی، نکته اصلی این است که انسانها به عنوان یک گونه، از استفاده از زبان برای به اشتراک گذاشتن دانش خود، هم در زمان حال و هم در طول نسلها، بسیار سود میبرند. با این درک، زبان چیزی است که سسیلیا هایِس، دانشمند شناختی، آن را «ابزارک شناختی» (Cognitive Gadget) مینامد که «انسانها را قادر میسازد تا با کارایی، وفاداری و دقت فوقالعادهای از دیگران بیاموزند.»
شناخت ما به دلیل وجود زبان بهتر میشود—اما توسط آن خلق یا تعریف نمیشود.
اگر توانایی صحبت کردن از ما گرفته شود، باز هم میتوانیم فکر کنیم، استدلال کنیم، باورهایی را شکل دهیم، عاشق شویم و در دنیا حرکت کنیم؛ گستره آنچه میتوانیم تجربه و دربارهاش فکر کنیم، همچنان وسیع باقی میماند.
اما اگر زبان را از یک مدل زبان بزرگ حذف کنید، به معنای واقعی کلمه هیچ چیز باقی نمیماند.
یک علاقهمند به هوش مصنوعی ممکن است استدلال کند که هوش در سطح انسان لزوماً نیازی به عملکرد مشابه شناخت انسان ندارد. مدلهای هوش مصنوعی با استفاده از فرآیندهایی که با آنچه ما انجام میدهیم تفاوت دارند، از عملکرد انسان در فعالیتهایی مانند شطرنج پیشی گرفتهاند، بنابراین شاید بتوانند از طریق روشی منحصر به فرد مبتنی بر استخراج همبستگیها از دادههای آموزشی، به ابرهوش تبدیل شوند.
شاید! اما دلیل واضحی برای این تصور وجود ندارد که بتوانیم به هوش عمومی—نه بهبود وظایف با تعریف محدود—از طریق آموزش مبتنی بر متن دست یابیم. به هر حال، انسانها انواع دانش را دارند که به راحتی در دادههای زبانشناختی قابل جمعبندی نیست—و اگر در این مورد شک دارید، به این فکر کنید که چگونه میدانید دوچرخه سواری کنید.
در واقع، در جامعه تحقیقات هوش مصنوعی، آگاهی فزایندهای وجود دارد که LLMها به خودی خود، مدلهای ناکافی برای هوش انسانی هستند. به عنوان مثال، یان لِکون، برنده جایزه تورینگ برای تحقیقات هوش مصنوعی و یک منتقد برجسته LLMها، هفته گذشته نقش خود را در متا ترک کرد تا یک استارتاپ هوش مصنوعی برای توسعه آنچه مدلهای جهانی نامیده میشود، تأسیس کند: «سیستمهایی که دنیای فیزیکی را درک میکنند، حافظه پایدار دارند، میتوانند استدلال کنند و میتوانند توالیهای عملی پیچیده را برنامهریزی کنند.» و اخیراً، گروهی از دانشمندان برجسته هوش مصنوعی و «رهبران فکری»—از جمله یوشوا بنجیو (برنده دیگر جایزه تورینگ)، اریک اشمیت مدیر عامل سابق گوگل، و گری مارکوس، منتقد مشهور هوش مصنوعی—گرد هم آمدند تا یک تعریف کاری از AGI را تدوین کنند: «هوش مصنوعی که میتواند با قابلیت انعطافپذیری و مهارت شناختی یک فرد بالغ تحصیلکرده برابری کرده یا از آن پیشی بگیرد» (تأکید اضافه شده است). آنها به جای برخورد با هوش به عنوان «یک ظرفیت یکپارچه»، پیشنهاد میکنند که یک مدل از شناخت انسانی و مصنوعی را بپذیریم که منعکس کننده «یک معماری پیچیده متشکل از بسیاری از تواناییهای متمایز» باشد.
آنها استدلال میکنند که هوش چیزی شبیه به نمودار عنکبوتی (که در متن اصلی ارائه شده) به نظر میرسد.
آیا این پیشرفت است؟ شاید، تا جایی که ما را از جستجوی بیمعنای دادههای آموزشی بیشتر برای تغذیه سرورها فراتر میبرد. اما هنوز هم مشکلاتی وجود دارد. آیا واقعاً میتوانیم قابلیتهای شناختی فردی را جمع کنیم و حاصل جمع را هوش عمومی تلقی کنیم؟ چگونه تعریف کنیم که چه وزنهایی باید به آنها داده شود، و کدام قابلیتها گنجانده و حذف شوند؟ منظور ما دقیقاً از «دانش» یا «سرعت» چیست و در چه زمینههایی؟ و در حالی که این کارشناسان موافقند که صرفاً مقیاسدهی مدلهای زبانی ما را به آنجا نخواهد رساند، مسیرهای پیشنهادی آنها برای پیشروی بسیار پراکنده است—آنها یک هدف بهتر را ارائه میدهند، نه یک نقشه راه برای رسیدن به آن.
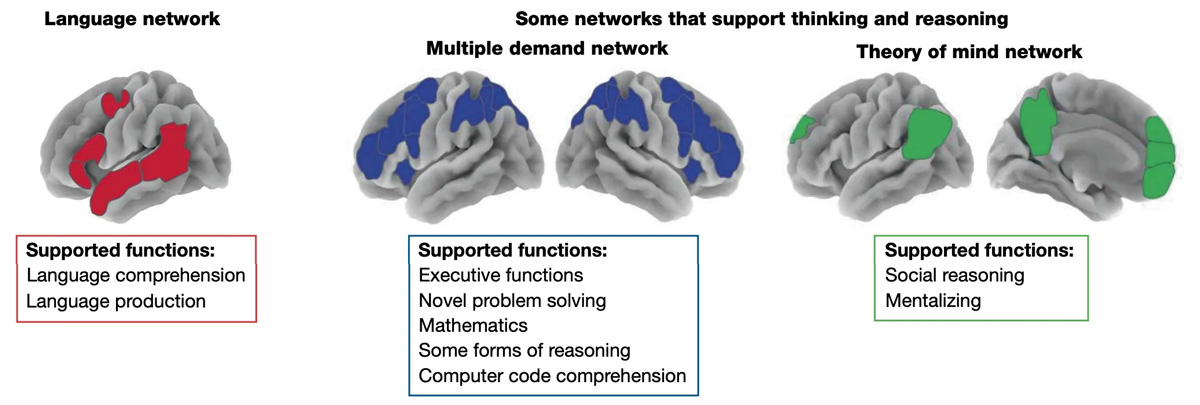
به هر حال، بیایید فرض کنیم که در آیندهای نه چندان دور، ما در ساخت یک سیستم هوش مصنوعی که در طیف گستردهای از وظایف چالشبرانگیز شناختی که در نمودار نشان داده شده، به خوبی عمل میکند، موفق میشویم. آیا به ساخت یک سیستم هوش مصنوعی دست خواهیم یافت که دارای نوعی از هوش است که منجر به کشفیات علمی متحولکننده میشود، همانطور که مدیران عامل شرکتهای بزرگ فناوری وعده میدهند؟ لزوماً خیر. زیرا یک مانع نهایی وجود دارد: حتی تکرار روشی که انسانها در حال حاضر فکر میکنند، تضمین نمیکند که سیستمهای هوش مصنوعی بتوانند جهشهای شناختی را که بشریت به دست میآورد، انجام دهند.
ما میتوانیم اعتبار مفهوم «پارادایمهای علمی»، یعنی چارچوبهای اساسی برای درک دنیای خود در هر زمان معین، را به توماس کوهن و کتابش ساختار انقلابهای علمی بدهیم. او استدلال کرد که این پارادایمها نه در نتیجه آزمایشهای تکراری، بلکه زمانی «تغییر» میکنند که سؤالات و ایدههای جدیدی پدیدار شوند که دیگر در توصیفات علمی موجود ما از جهان جای نمیگیرند. به عنوان مثال، اینشتین نسبیت را پیش از آنکه هر شواهد تجربی آن را تأیید کند، تصور کرد. بر اساس این مفهوم، ریچارد رورتی فیلسوف، مدعی شد که زمانی که دانشمندان و هنرمندان از پارادایمهای موجود (یا واژگان، آنطور که او نامید) ناراضی میشوند، استعارههای جدیدی خلق میکنند که باعث ایجاد توصیفات جدیدی از جهان میشود—و اگر این ایدههای جدید مفید باشند، آنگاه به درک مشترک ما از آنچه حقیقت است تبدیل میشوند. به این ترتیب، او استدلال کرد که «عقل سلیم مجموعهای از استعارههای مرده است.»

همانطور که در حال حاضر تصور میشود، یک سیستم هوش مصنوعی که چندین حوزه شناختی را پوشش میدهد، میتواند، ظاهراً، آنچه یک انسان هوشمند عمومی در پاسخ به یک ورودی معین انجام میدهد یا میگوید، پیشبینی و تکرار کند. این پیشبینیها بر اساس جمعآوری و مدلسازی الکترونیکی هر داده موجودی که به آنها داده شده است، انجام خواهد شد. آنها حتی میتوانند پارادایمهای جدید را به روشی شبیه به انسان در مدلهای خود بگنجانند. اما آنها دلیل آشکاری برای ناراضی شدن از دادههایی که به آنها داده میشود، ندارند—و به تبع آن، دلیلی برای انجام جهشهای بزرگ علمی و خلاقانه ندارند.
در عوض، بدیهیترین نتیجه چیزی جز یک مخزن عقل سلیم نخواهد بود. بله، ممکن است یک سیستم هوش مصنوعی دانش ما را به روشهای جالب بازترکیب و بازیافت کند. اما این تنها کاری است که قادر به انجام آن خواهد بود. این سیستم برای همیشه در واژگانی که ما در دادههایمان کدگذاری کردهایم و آن را بر اساس آن آموزش دادهایم، به دام خواهد افتاد—یک ماشین استعاره مرده. و انسانهای واقعی—که فکر میکنند، استدلال میکنند و از زبان برای برقراری ارتباط افکار خود با یکدیگر استفاده میکنند—همچنان در خط مقدم متحول کردن درک ما از جهان باقی خواهند ماند.
به مطالعه ادامه دهید:
راز «نگهداری دائمی»: استراتژی جدید سرمایهگذاران برای کسب سود از شرکتهایی فاقد VC
معرفی گوشی جانسخت OnePlus 15R، تبلت Pad Go 2 و ساعت هوشمند Watch Lite
ایرانسل به پویش ملی «بساز مدرسه» پیوست
هر سال چند پلاک موتور به دلیل تخلفات سنگین فک میشود؟ آمار ۵ سال اخیر
نوشته هوش مصنوعی ابرقدرت نیست؛ «زبان» با «هوش» فرق دارد! اولین بار در موبایلستان. پدیدار شد.
اولین باشید که نظر می دهید